Forecast families: a method to investigate what skills improvements have societal value
by Charles Rougé, Andrés Peñuela and Francesca Pianosi
Numerical weather predictions – and hydrological forecasts that are generated based on these data products – are becoming increasingly accurate. So far this irrepressible (but slow?) march forward of hydro-climatic forecasting systems has mainly looked at the relationship between the predictive power of a forecast (its skill) and its societal benefit (its value) as a one-way street: here is a forecast product, how can it be used? To change this, one would need methods that can go the other way around and ask the question: what improvements of a forecast would provide the most value?
The question is important because if a forecast’s value increased faster than its skill (similar to the blue line in Figure 1a), then even slight improvements in forecast skill might make them much more useful for water managers. Such nonlinearity may exist given that, while the skill is a property of the forecast alone, its value for water management also depends on the physical configuration and the operational objectives of the water resource system (Figure 1b).
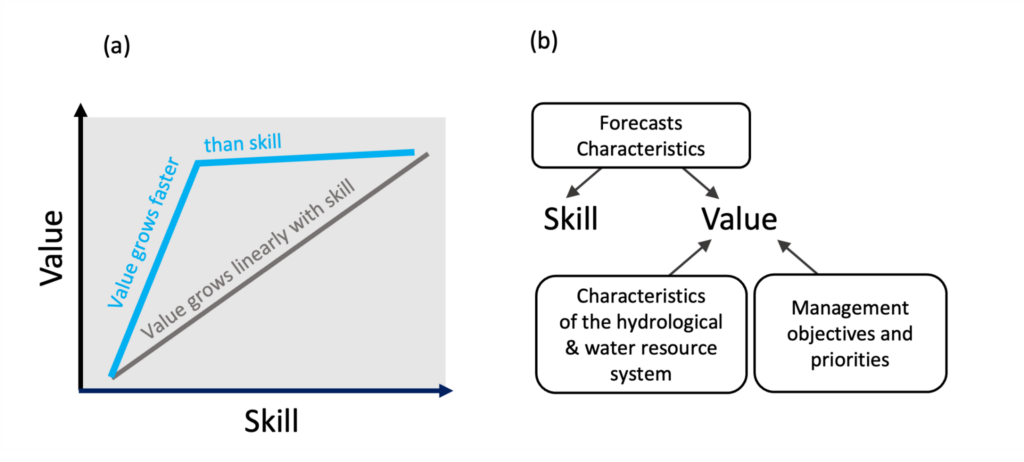
Figure 1. (a) An idealised skills vs. value graph. (b) Some factors that might influence a forecast’s skill and societal value.
The challenge
As difficult as focusing on skill improvements first is, going the other way might prove even trickier. In fact, evaluating what improvements in forecast would be valuable necessitates an ability to generate a synthetic forecast that represents an incremental improvement on an existing forecast. But what does that look like?
Our proposed solution: “Forecast families”
There is a lot to untangle here, with new methods a necessary entry point towards investigating the other two difficulties. Our work proposes “forecast families” that are a linear combination of a hindcast with the historical data. The advantages of this method are:
- Simplicity: we show this is a simple, straightforward way of generating synthetic forecasts of any desired skill that by construction, are similar to the original forecast.
- Easy interpretation: this clear link between the synthetic forecast and an actual forecast product makes the results easy to interpret.
- Preserved correlation: The linear scaling also preserves the correlation structure between forecasts of any weather variable, issued at different points in time and space and with different lead times, as well as correlations with the actual weather data.
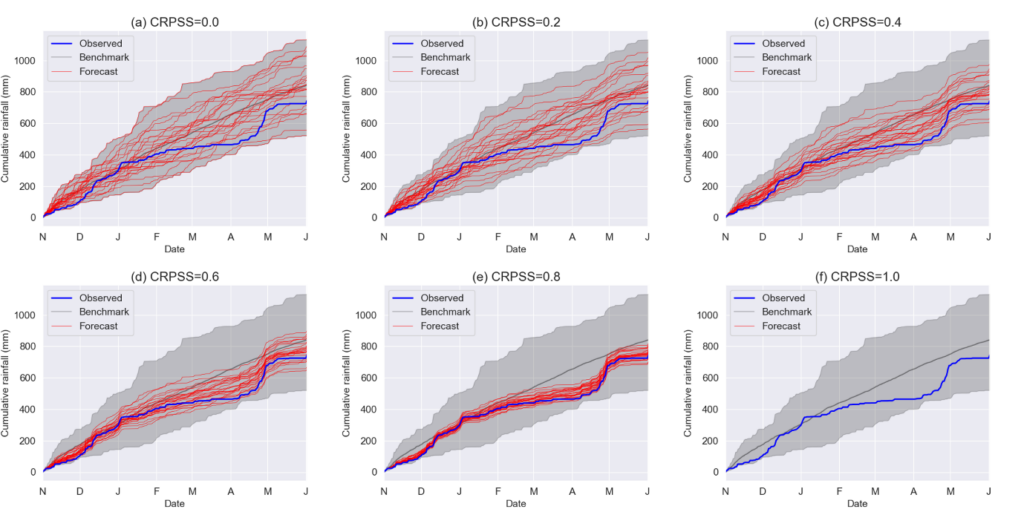
Figure 2. Forecast ensembles as the skill evolves from the original bias-corrected ECMWF forecast (CRPSS=0 as computed with this forecast as benchmark) to a perfect forecast. This is a 7-month seasonal forecast for rainfall issued on 1 November 2011.
Case study application
Case in point, Figure 2 above with ensembles and the most common measure of ensemble performance, the continuous ranked probability score (CRPS), and the skill measure derived from it, the CRP skill score (CRPSS). The ensemble used here is cumulative rainfall forecast by ECMWF-SEAS5 for a catchment in southern England, forecast issued on 1 November 2011, vs. the actual cumulative rainfall. Skill evolves from 0 (Figure 2a) where the ensemble is the ECMWF-SEAS5 hindcast, to a perfect forecast with a skill of 1 (Figure 2f), by increments of 0.2. The plot shows what improving skill could mean in practice for CRPSS: it can be achieved simply by reducing the uncertainty within the ensemble, as long as this does not affect how many ensemble members are above (or below) what actually happens.
We applied the forecast families method to the same case study and model setup investigating the value of seasonal forecasts as described in this previous HEPEX blogpost. This enabled to systematically investigate the relationship between skill and value for different operational preferences, in a configuration where the two competing objectives are: (i) to refill a two-reservoir system during winter, and (ii) to minimize pumping costs in refilling reservoirs. Using the forecast families methodology, this case study led to the following key findings:
- Non-linear skill-value relationship: The relationship between skill and value is highly non-linear. This is partly due to the fact that the relationship between skill and value is highly dependent on extreme events, i.e. here, the dry years.
- Operational preferences mediate this dependence: For instance, in a situation with two consecutive dry years, we showed that with our most balanced approach between our two objectives, the second dry year dominated the value gains, whereas for operations that strongly prioritize resource availability, value gains were almost exclusively in reducing pumping costs, with a better repartition among years.
- Targeting skill improvements: The value gains from the first increment in skills also depend on years and operational preferences, and the method can help identify when they would happen. That can help to target skill improvements in the future!
Future applications
This is a short summary of key snippets from our study which for demonstration purposes, used the same skills across all years and variables, with large skill increments. However, future applications trying to have a finer understanding of when and how small skill increments can deliver value could unlock valuable two-way collaborations between the experts who produce hydro-meteorological forecasts and those who use them!
Resources
On that note, there are signs that researchers on the water resource management side of things are excited by the potential of using this method: the paper has been recognized as the “2024 Best Research-oriented Paper” from the Journal of Water Resources Planning and Management. It is available here, and the method’s Python code and demonstration notebook are available here.
March 25, 2024 at 10:23
Very nice blog and congratulations on your award. I wonder .. do we have the same understanding on value & how would a different definition influence your method?