Nice hydrographs for everyone, from everyone: Introducing eWaterCycle II
Contributed by Rolf Hut, TU Delft.
“Nice hydrographs! Can you now compare your model to ‘that other hydrology groups model’?”
The PhD student suppresses the urge to roll her eyes. Her supervisor is asking her to go back into code-hell. That other model is written in Fortran and she works in Python. It took her two months to get the Python model used in her group running in the first place. Realizing she needed to install an obtuse library on her computer needed by a hidden part of the hydrological model that the post-doc who left science four months ago had added took her two weeks alone. She doesn’t look forward to installing another institute’s favorite model just to compare its output to hers. It will mean getting back behind the computer working on getting someone else’s code to run and not on using her hydrology skills for a few more weeks.
Scientifically her supervisor is right, of course. If a hydrologist improves an existing model ideally one would not only like to compare the model output to observations, but also to other models. However, running someone else’s model is often a pain. It is no coincidence that model comparison papers often involve all the groups responsible for the different models being run in the study.
As Chris Hutton et al. said in an opinion paper: “Most computational hydrology is not reproducible, so is it really science?”. In the ensuing discussion Nick van de Giesen, Niels Drost and I argued that to increase the reproducibility, but also the reusability, of hydrologic models we should present them in such a way that they can be run independent of a local computer, i.e. in virtual machines or the lightweight equivalent: containers. In the eWaterCycle II project we are putting our money[1] where our mouths are and are building a system that easily lets hydrologists do just that.
The goal we have for the eWaterCycle II project is to provide the hydrological community with tools that:
- Allow the use of a wide variety of models, written in different programming languages, without having to learn those languages.
- Run models needing large amounts of memory and CPUs.
- Have access to all the relevant datasets from the community (forcing, observations).
- Allow advanced use cases such as data assimilation and model coupling studies.
- Allow the sharing of models with the entire community, both for citing (DOIs) and re-use.
Ultimately providing hydrologists with a toolset that allows them to run each other’s models, but also adapt, couple, and in general tinker with models without the headache of having to delve into each other’s detailed code.
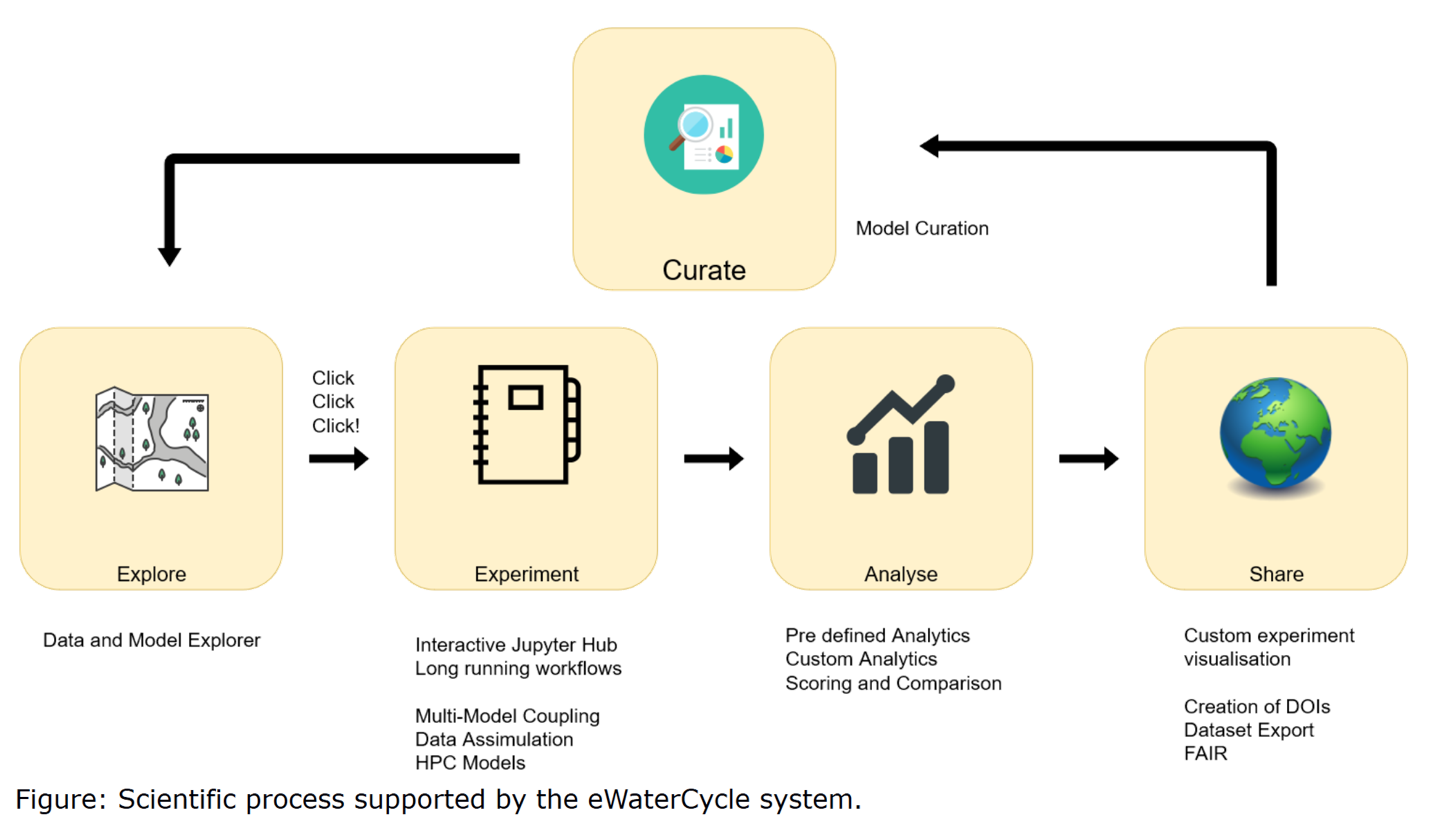
Currently six months into this three year project, we have created a “minimal viable product (MVP)”[2], a first, duck-taped version of what we intend to build . To gauge in the hydrological community if we’re moving in the right direction. In our MVP scientists can:
- Get started with modelling without installing a single piece of software[3].
- Run any of the available models within minutes.
- Develop code quickly in a notebook environment.
The MVP currently runs on a cloud computer with limited compute and is far from production ready, so access is restricted to project members. Medio 2019 we intend to deploy the system on more robust infrastructure and open up the environment for the entire hydrological community to try out. The video below shows a screencast of the MVP in action. In it we select a model from our experiment finder. We automatically generate a jupyter notebook with python code that runs the model and plots a hydrograph. The model is not part of the notebook: it is a process in a separate container that talks to the notebook.
Had the model of ‘that other hydrology group’ been in our system, then the PhD student from the start of this blog wouldn’t have to despair: three clicks and she could have looked at a hydrograph. Our MVP allows hydrologists to quickly run pre-existing models, compare outputs of different models and change the model state during the run to do experiments. We hope that our project contributes to a future where hydrologist can produce reproducible results and thus can build on each others work more easily. If you would like to be among the first to work with the system, if you want to add your model to it, or if you just want to provide us feedback, please get in touch!
1. Well, our funder’s money, but you get the point. ↑
2. A method of developing copied from start-up culture and software development. One of the benefits of working with a multidisciplinary team of experts is that they provide one with new ways of approaching a project. ↑
3. Well, ok, a web browser. ↑
This blog by Rolf Hut was originally posted on www.ewatercycle.org and is re-published here with permission.
0 comments