Interview with Beth Ebert: What is good forecast verification?
Contributed by Tom Pagano, a HEPEX guest columnist for 2014
The opinions expressed here are solely the author’s and Dr. Ebert’s and do not express the views or opinions of their employer or the Australian Government.

Dr. Beth Ebert
HEPEX is spurring interest in Hydrologic Forecasting Science as its own field of study, with forecast verification (assessment of the quality of forecasts) a related and essential topic. Forecast verification is also of interest to operational services – the Director of the Australian Bureau of Meteorology recently stated “If you are in the forecast business then you must be in the verification business”. Today we are talking with Dr. Beth Ebert about “What is good forecast verification?”
Dr. Ebert developed her interest in verification during her years at the Bureau of Meteorology. With John McBride, she pioneered an object-based method for spatial verification of weather forecasts that recognizes when a forecast map is “good” in an overall sense, but where the features are in the wrong location, or the storms are moving at the wrong speed.
She is a founding member of the World Weather Research Programme’s (WWRP) verification working group, which promotes verification and verification best practices through webpages and training. She is currently the Research Program Leader of the Weather and Climate Information Program in the Centre for Australian Weather and Climate Research. I sat down with her to discuss some issues facing forecasters and researchers today:
Pagano: In your opinion, what makes for useful verification?
Ebert: It needs to be done in a timely fashion so that the results come out while the event is still fresh in people’s memories, so they can learn from it. It should to be done consistently through time so it’s possible to measure whether forecasts are getting better. Make it meaningful to the user- there is no point in using scores that people do not understand or cannot relate to.
One of the things meteorologists want to get more into – and hydrology is doing a good job of this – is working with users to understand what error information would be most useful to them. Do you need to know biases? Are you interested in average errors, extreme errors? Which weather elements? Maybe you care less about temperature because you are mainly interested in heavy rainfall.
Pagano: And what is the purpose of verification?
Ebert: There are several purposes. The users want to know how much they can trust the forecasts. The forecast developers want to know if what they are making is any better than the current system. Forecasters need to know the quality of the guidance they use to prepare their forecasts. Managers need to know if they are getting a return on their investments in research and system upgrades.
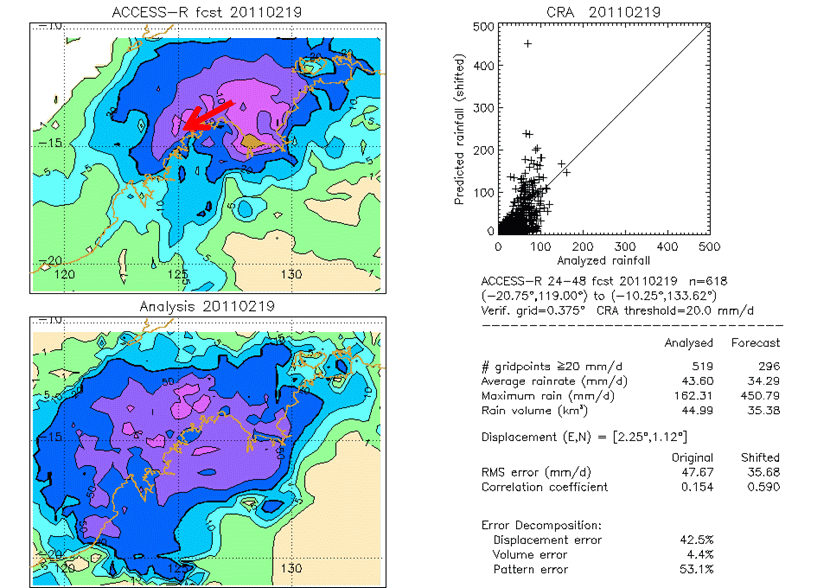
Analysis of the Contiguous Rain Area (CRA) of a precipitation forecast (top left) issued by the Australian Numerical Weather Prediction model compared to the observed (bottom left). The event’s forecast volume is relatively good, but most of the error is in the storm’s location and spatial pattern.
Pagano: Who do you feel is doing verification very well?
Ebert: I think the UK Met Office does a really good job. They have both a research and an operations verification department. The research department is focused on metrics that the modellers can use to see the benefits of, for example, a new data assimilation scheme or higher spatial resolution. The operational department is targeted to the users- they have aviation verification, for example, with a flight time error – and are using measures developed with industry partners that are meaningful to those users.
Pagano: What are easy mistakes for those new to the field?
Ebert: Early on, I made the mistake of mixing regimes, like calculating annual statistics for rainfall forecasts in the tropics. They looked really good, better than rainfall forecasts for the mid-latitudes, but that was just because the model could tell that the wet season was wet and the dry season was dry. Well, it does not take much of a model to do that!
There is a great temptation to lump many statistics into one composite score because administrators want “one number”, as in, “Is the number getting better? Is the line going up?” But it does not give you very meaningful information on why things are getting better or worse. Sometimes people try to develop a new ad hoc score, not realizing that there is a whole science of scores that goes back to the 1800s.
Pagano: I once tried to list all the categorical [contingency table] scores and it filled up a whole slide with tiny font.
Ebert: Oh yeah, the Jolliffe and Stephenson book [on forecast verification] has a two page list of verification scores of binary (“yes/no”) forecasts and their definitions.
Pagano: And some of them are identical, but just named differently, because the researchers were not aware of what already existed.
Ebert: There are still areas of new scores being invented, particularly verification of extreme events when you typically have a small sample size. Chris Ferro and David Stephenson are doing some exciting work in this area.
Pagano: What is your perspective on verification in hydrology?
Ebert: Hydrologists often forecast at a single location, so it is more of a time series problem than a spatial problem. I have been impressed by Julie Demargne and James Brown’s work in verifying in a way that is meaningful to hydrologists. Instead of the same old scores, they have developed targeted plots and diagnostics. Their EVS (Ensemble Verification System) is quite nice.
Ensemble forecasting and ensemble verification have been coming for some time but they have caught on more slowly in hydrology than meteorology- I think HEPEX is a great initiative to move things forward. For many years in meteorology, we have been objectively blending many bias-corrected model outputs to make consensus forecasts. It is just simple statistics but it improves the results a lot. I have not seen much of that in hydrology.
Pagano: Speaking of objective blends, would you verify forecasts from a person and a model differently?
Ebert: With systematic verification, you are often putting a lot of information into one pot. The times when the human would make a big difference might be one or two events, but these might be high impact cases where the person really saved the day. Just lumping everything together and saying “The human is only 2% better than the model” might be hiding that the model and the forecaster are roughly the same 98% of the time, but then 2% of the time, the person is doing something quite important.
Pagano: Do you see any frontiers in the field?
Ebert: Things are probably changing as you are getting into distributed hydrologic models and making spatial inundation forecasts. You likely do not have the same kind of displacement errors that you would in meteorology (your river remains fixed), but how do you describe the quality of a three- to four- dimensional hydrologic forecast, in ways that are meaningful to both developers and users? Ensemble hydrologic verification is also a hot topic, where much could be done.
If you would like to read more about HEPEX’s forecast verification activities, there are a series of posts here:
- What do we mean by forecast verification? What are the goals of verification?
- Different attributes of forecast quality and commonly used verification metrics.
- What practitioners and researchers should consider when verifying forecasts?
- What are the challenges and research needs in ensemble forecast verification?
October 29, 2014 at 16:08
Hi Beth / Tom, a nice read, thank you.
I’ll be looking at your work / that of WWRP in more detail when it comes to evaluating GloFAS for humanitarian organisations: it’s possible that if they make their decisions at a regional level, then the model could forecast a flood in a neighbouring catchment (because of spatial error in rainfall) but it still be useful. The traditional hydrological verification methods might not give any credit to the model for this kind of spatial error.
As we move towards forecasting inundation rather than just river flow, verifying spatial inundation forecasts will become more tempting, though I’m very wary of them, and in my previous research in flood inundation modelling I grappled with their problems.
The traditional contingency table scores are not robust for inundation, despite how often they are used. As you said, the river remains fixed, so forecasting inundation correct close to the river is not difficult if you have forecasted it correct close to the flood margin. The score is then dependent on the ratio between the length of the perimeter of the flood and its area. This effect means that the larger the flood, or indeed the more shallow the gradient of the floodplain, the better your contingency table-based score looks.
This all leads to a shameless plug for one of my papers, which hopefully explains what I’m trying to say much better! http://onlinelibrary.wiley.com/doi/10.1002/hyp.9979/abstract