Testbeds in HEPEX: lessons learned and way forward
Contributed by Maria-Helena Ramos and Andy Wood
How were testbeds initially defined?
The testbed activity was first summarized in the 2006 Implementation Plan for The Hydrological Ensemble Prediction Experiment (HEPEX) (Wood et al., 2006). In the first two HEPEX workshops (Reading in 2004 and Boulder in 2005), it was decided that HEPEX’s projects and activities would be organized in pilot ‘testbeds’ (download here the proposal from the Boulder 2005 workshop).
“The test beds are collections of data and models for specific basins or sub-basins, where relevant meteorological and hydrological data has been archived.
In these test-beds, it is expected that different forecast approaches and tools can be demonstrated and inter-compared.
The development of these tools and their demonstration in the test-bed basins are central activities for the implementation phase of HEPEX, along with inter-comparison of various hydrological prediction methods and linkages to users.”
Testbeds demonstration projects were to be the primary mechanisms to answer HEPEX scientific questions around its six topics over a range of scales and climates (at that time, topics were Downscaling, Data management, Hydrological uncertainty, Data assimilation, Community Hydrologic Prediction System – CHPS – software, Socio-Economic applications).
Regardless of geographical domain, testbeds should:
- focus on one or more clearly defined HEPEX scientific topic,
- have the potential to develop data resources needed for community experiments, and
- include, when possible, an active participation of users.
Annual testbed project reports were listed as HEPEX deliverables, and shared datasets and forecast tools were foreseen.
HEPEX testbeds across the world
The first HEPEX testbeds were established during the 2nd HEPEX workshop in Boulder in 2005. They had different objectives, including (Schaake et al., 2006):
- to demonstrate the importance of atmospheric and hydrologic modelling for medium-range forecasting on large basins;
- to foster the development of reliable and skilful operational real-time forecasts of river discharges at several time-scales;
- to explore the use of new data on weather ensembles in hydrological forecasting;
- to test routines for bias removal and methods for flood forecasting based on threshold exceedances;
- to develop hydrologic ensemble forecasting techniques with a focus on monthly to seasonal lead-times;
- to assess uncertainties in hydrological ensembles;
- to identify the space-time scales for which forecast skill is present for different variables and develop methods to download, extract and combine information at different space-time scales;
- to investigate the relative merit of the different sources of prediction uncertainties, including model inputs, model parameters and model structure;
- to address the advantages and limitations of different methods for characterizing and reducing uncertainty in hydrologic model simulations.
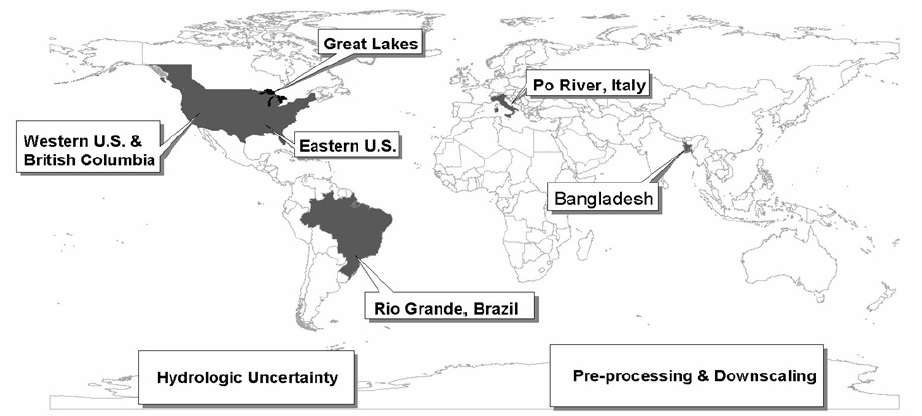
First test-beds defined in HEPEX in 2006
Ten testbeds: six site-specific and four cross-cutting topics testbeds
Six testbeds were conceived to be site-specific testbeds:
- Great Lakes and St. Lawrence River in Canada/U.S. (see description and 2006 report)
- Brahmaputra and Ganges Rivers in Bangladesh (see description and 2006 report)
- Rio Grande river basin in Brazil (see description and 2006 report)
- Po river basin in Italy (see description)
- Western U.S./British Columbia (see description)
- Southeast U.S. (see description and 2006 report).
Four testbeds were cross-cutting topics test-beds, dedicated to the development and intercomparison of procedures that cross-cut the other six testbeds and HEPEX topics:
- Statistical downscaling (see description and 2006 report)
- Hydrological uncertainty (see description)
- Ensemble observations of rainfall (see description)
- Verification (see description)
Contribution to HEPEX and its topics
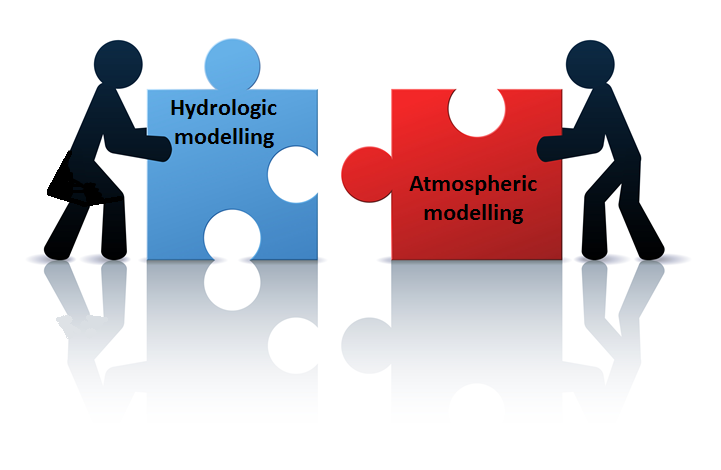 “(…) hydrological modelling experiments can be used to evaluate the quality of an ensemble prediction system, and provide feedback to the atmospheric modelling community, thus helping to improve the quality of the meteorological forecasts”, Fortin and Pietroniro (2006) reporting about the Great Lakes test-bed.
“(…) hydrological modelling experiments can be used to evaluate the quality of an ensemble prediction system, and provide feedback to the atmospheric modelling community, thus helping to improve the quality of the meteorological forecasts”, Fortin and Pietroniro (2006) reporting about the Great Lakes test-bed.
Testbeds clearly brought meaningful scientific and technical contributions to HEPEX. They contributed to projects like the Bangladesh forecasting system and the EFAS European Flood Awareness System, as well as to improvements in the atmospheric-hydrologic modelling of complex systems like the Great Lakes or the Rio Grande river basin in Brazil.
Additionally, testbeds prompted the development of new methods for statistical correction and bias removal for atmospheric forcings and streamflow forecasts. Some of the advances in forecast verification and data assimilation are also the results of the efforts the community put into HEPEX testbeds (oral communications given at the various HEPEX workshops allow to follow the developments of some of the testbeds initially proposed within HEPEX).
Testbed leaders and co-learders are acknowledged for their important contributions:
- Vincent Fortin and Alain Pietroniro, for the Great Lakes, Canada/US testbed
- Tom Hopson and Peter Webster, for the Bangladesh testbed
- Carlos Tucci, Walter Collischonn, Robin Clarke, Pedro Silva Dias and Gilvan Sampaio de Oliveira, for the Rio Grande river basin, Brazil testbed
- Jutta Thielen and Stefano Tibaldi, for the Po river basin, Italy testbed
- Frank Weber, Andy Wood, Kevin Werner and Tom Pagano, for the Western Basins, U.S./B.C. testbed
- Eric Wood and Lifeng Luo, for the Southeast Basins, U.S. testbed
- Martyn Clark and John Schaake, for the Statistical downscaling testbed
- Martyn Clark, Jasper Vrugt and Hamid Moradkhani, for the Hydrologic uncertainty testbed
- Tim Bellerby, for the Ensemble Representations of Rainfall Observation and Analysis Uncertainty testbed
- Julie Demargne, Kristie Franz and James Brown, for the Verification testbed
However, questions remain…
Some testbeds became active, generated results or findings, while others didn’t. HEPEX attempted to form testbeds around a number of themes, but most of them did not take off, at least in the ‘testbed’ form that was envisioned.
It seemed that there was some expectation that each testbed would involve an open group of people contributing to a community resource of data or methods, facilitating intercomparisons and exploration, and reporting back to HEPEX. This was however not observed in all of the proposed testbeds.
To be viable and remain active, a testbed needed perhaps more involvement within other HEPEX activities (e.g., by linking different work-groups) or be associated to some funded project. Several questions remain:
- What makes a successful testbed?
- How HEPEX can make sure that any future testbeds or experiments become ‘real’?
- Perhaps one issue is that we don’t really have a single concept of a testbed: so what is a test-bed? Can it be just one person working on a project? Does it have to share data or methods back to the community?
In which direction should we go now?
Questioning ourselves about the way testbeds worked (or not) is a way for HEPEX to learn from earlier missteps and not put energy into them again if they have a low probability of working out. Important issues were raised in the beginning of the establishment of the testbeds and are still HEPEX challenges:
- How to link different experiments?
- How to make available all the necessary data sets to be used in intercomparison studies?
- How to involve users in HEPEX experiments?
- How to assure a follow up of the activities and efficiently share acquired knowledge and achievements?
Recently, HEPEX activities have also focused on HEPEX Experiments. Intercomparison experiments were in fact included in HEPEX activities since the beginning, together with testbeds, workshops and meetings. As more and more methods have been developed for forecast pre- and post-processing, verification and data assimilation, intercomparison studies have gained in importance.
Experiments are less open ended comparatively to testbeds, and have more defined deliverables, which can give them a stronger chance of working. Besides, their results can be more easily transposed to other river basins.
But, here again we need to have a clear concept of an experiment. Currently, a HEPEX experiment is characterized by:
- a focused objective related to one or several of the main themes of HEPEX (pre- or post-processing, data assimilation, verification, communication and use) and involving hydrological ensemble prediction for short-, medium or long-term forecasting,
- accessible datasets, with dedicated data repositories (e.g., ftp sites) where data can be downloaded and results uploaded by participants of the experiment,
- a timeline to help participants in following the different developing phases of the experiment: data preparation, data availability, model(s) running, results analyses and communication.
Experiments can last one year or more, depending on the activities envisaged and the involvement of the community. Overall, an experiment may promote an intercomparison of methods, test new data, techniques and approaches on a variety of catchments or situations. Codes, data and description need to be made available to anyone who wants to participate.
Currently, one HEPEX experiment is ongoing, the intercomparison of post-processors. Preliminary studies have been carried out for a THEPS Experiment, using the THORPEX/TIGGE database (see general description, the 2005 proposal, and the 2009 proposal). Besides, there are plans to launch soon new experiments on Data Assimilation and Seasonal hydrological forecasting.
Previously defined testbeds can certainly still contribute to HEPEX activities and, most important, be rich sources of data to HEPEX experiments.
→ Do you want to participate to HEPEX Experiments or propose a new one?
Anyone can propose a HEPEX Experiment. Use the HEPEX mailing list to communicate with members and contact HEPEX co-leaders for any questions or suggestions.
→ Did you/Do you participate to a HEPEX testbed and want to tell us more about it?
Leave a reply here or propose a post providing more information and updated results to the community.
→ Do you have any suggestions about the way testbeds and experiments should be carried out in HEPEX?
All comments and suggestions are welcome!
==== UPDATE ====
Thank you to those that in answer to this post wrote about some of the HEPEX testbeds. Check the posts here:
0 comments