Verification of U.S. National Hurricane Center’s forecast advisories, 2006-2019
Below is a re-post of a blog post that I recently published at forecastverification.com, which is a small company that I operate in part-time (in addition to my hydrometeorologist job at Deltares). While hurricane forecasting is a little removed from hydrometeorology, I figured that the disciplines have sufficient overlap for this to be interesting to the HEPEX community also. Happy reading!
Introduction
Post Hurricane Irma’s passage over Florida, back in September 2017, I analysed the quality of the forecasts that had been issued by the US National Hurricane Center. When Hurricane Dorian made its way to the US coast, I showed the Irma blog post to my friend Chris, a traffic modeler and forecaster. In response, Chris raised the question of how NHC forecast quality had developed since.
Raising that question sufficed to rekindle my interest in hurricane forecasts and I decided to analyse the quality of the NHC forecasts over a wider range of events. The questions I attempted to answer are, How does forecast quality…
… vary by forecast lead time?
… develop over time?
… vary by storm type?
NHC forecast advisories
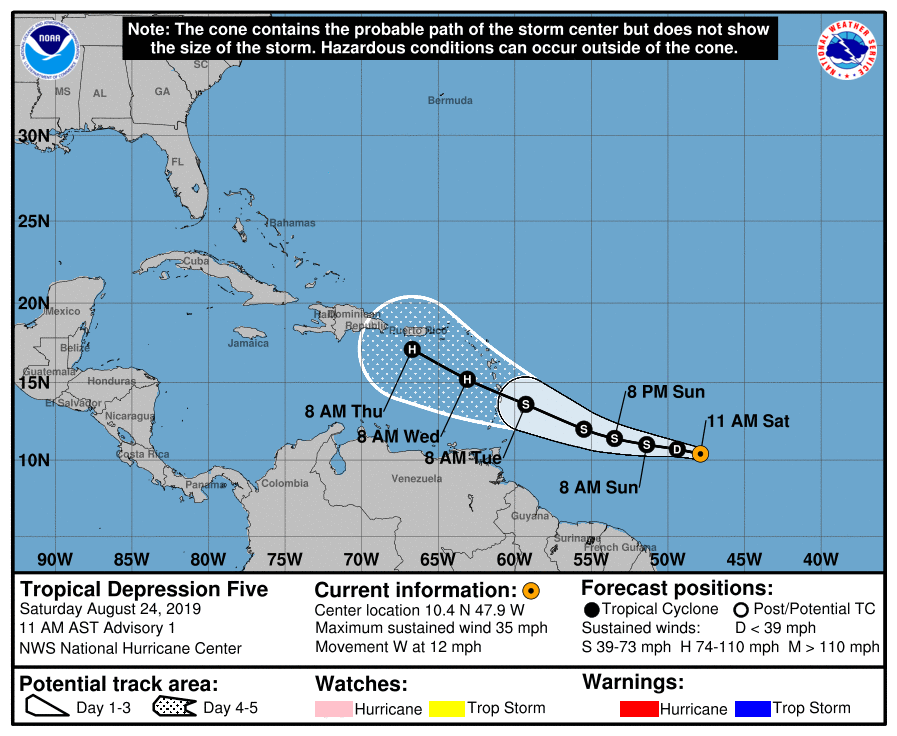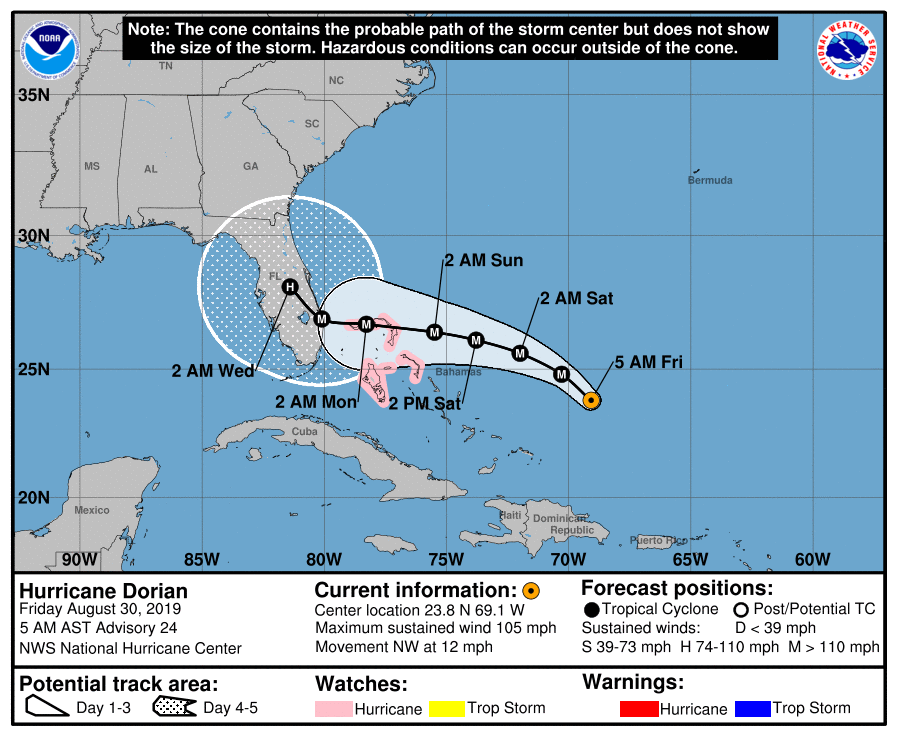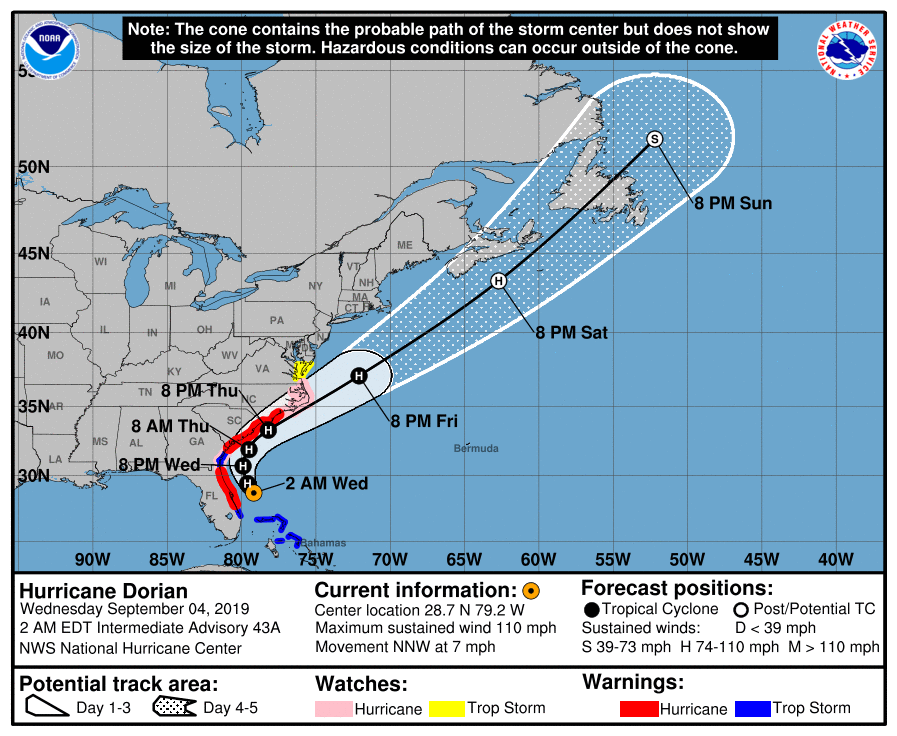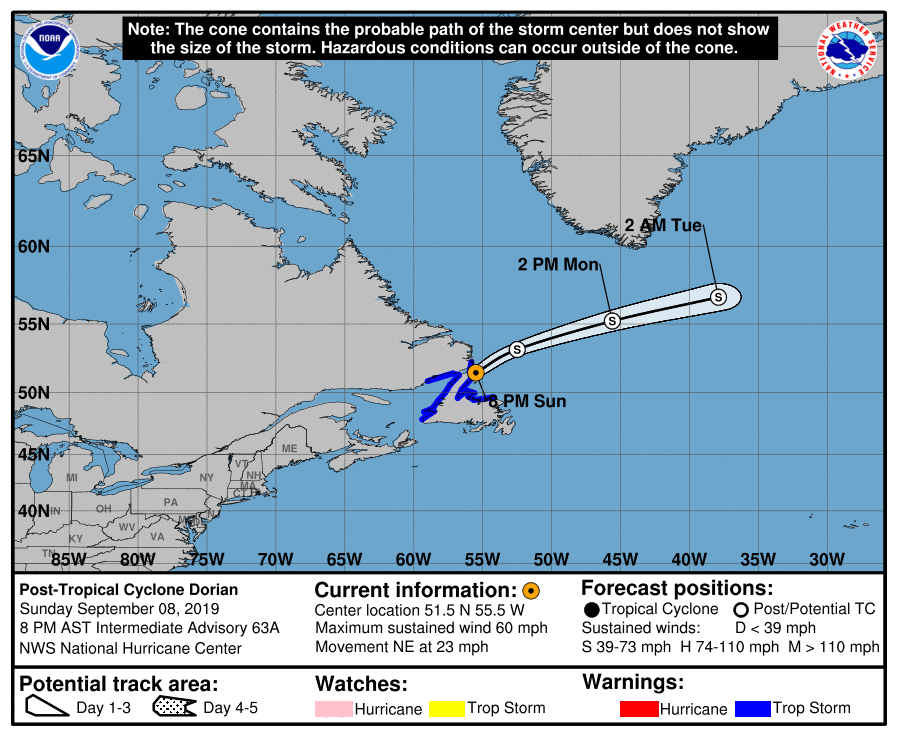
The US National Hurricane Center issues forecasts for the path and intensity of tropical depressions, storms and cyclones that may make landfall in the United States. These forecast advisories are posted on the NHC web portal in a number of formats including text bulletins and cone plots (links are examples of these). Below animation is a composite of all graphic advisories that had been issued during the lifetime of Hurricane Dorian.
Composite of NHC graphic advisories issued for Hurricane Dorian
If and when NHC is tracking a storm, its forecast advisories are issued at least four times daily at 3am, 9am, 3pm and 9pm (all times in UTC). The forecast cycle for each advisory begins 3 hours prior to the issuance of the advisory products, i.e. at 12am, 6am, 12pm or 6pm. In the present analysis, these latter “reference times” are referred to as T0 (“T-Zero”). Notably, the advisories contained predicted positions at T0 plus 12h, 24h, 36h, 48h, 72h, 96h and 120h – here referred to as forecast lead times.
The advisories contain both forecasted and observed locations of the storm’s center. This offers the possibility to verify the forecasts. In the present analyses, only forecasts of the location of the eye of storms is verified; no attempt was made to verify other variables such as wind speed and direction.
The data
The data was obtained by downloading text bulletins of the 2006 through October 2019 forecasts that have been archived on the NHC web portal and extracting the relevant passages. Below plot gives a sense of the number of storms that have been included in the analysis.
Some manual checks were done to ensure that the downloaded and parsed data correspond to the data in the original forecasts. Note that the data contains locations with a resolution of 1/10th of a degree. The advisories address the fact that there is observational uncertainty: the location is only accurate within so many nautical miles. In the present analysis, this observational uncertainty is not taken into account.
Results
Below plot shows forecast errors of all available pairs versus forecast lead time. As expected, the error grows with lead time. This is largely due to the chaotic nature of the atmosphere.
I then, for each lead time separately, plotted the median annual forecast error versus the year in which the forecast was issued. The plot shows a general decrease in forecast error from 2006 through 2014. Since that year, forecast errors have remained more or less constant – with a slight increase observed in the present calendar year 2019. While the median error only partly described the full record of errors, an analysis of error distributions (not shown here) yields similar results.
I subsequently explored how median annual forecast errors vary with storm types. The idea behind this is that the NHC may give more attention to hurricanes than to weaker storms, and that this attention may result in higher forecast quality. This appears to be confirmed by below graph.
From storm names, their gender may be ascertained. An interesting question then is whether a difference in forecast quality can be observed, depending on the storm gender. Indeed, below plot appears to suggest that females are less predictable than males – which many of us may either confirm or refute on the basis of personal, anecdotal evidence.
Discussion
In above analysis, ‘forecast quality’ was reduced to ‘characteristics of the difference between forecast and observed storm eye location’. Obviously, there is more to forecast quality than that. A more elaborate analysis would have to include a more robust statistical analysis of findings. It could also include further analysis of what factors contribute to forecast quality. For example, it may vary by basin (Atlantic versus Eastern Pacific versus Central Pacific), by forecaster, by the number of preceding storms within a season (due to increased experience of the forecasters) and by the level of potential adverse consequences. Also, it could well vary by factors such as level of agency funding, overall level of forecaster experience and many more.
Analysing the NHC advisories required a significant amount of resources and one could ask the question, Why bother? Indeed, this is a valid question. Verification, while fun, shouldn’t be done simply for the heck of it. Rather, there should be some wider objective – a set of questions that may be answered using the results of a verification exercise.
When I showed a first version of the present blog post to Chris, he asked me various questions, including
Has improved forecast quality resulted in increased benefits, in terms of damage reduction?
If so, how does that benefit relate to the investments made into improved forecasts?
Why has forecast quality kind of leveled off post 2014 or so?
Why are forecasts for hurricanes that much better than those for tropical storms of lesser magnitude?
What is the reason why some of the forecasts have errors in the magnitude of well over 1,000 miles?
These are questions he would not have asked unless he had seen the results of the analysis of forecast quality. The point I’m trying to make here is: forecast verification results in a set of questions that, in turn, may well lead to improved forecasts. And this is exactly one of the reasons why forecasts should be verified. And while it is important that forecasters verify their own forecasts, I would argue that forecast verification information should also be available to a wider audience than that. A large, diverse audience will ask questions that a smaller group would have never throught of – thus opening up novel avenues of improvement. Scary, yes – but so worthwhile.
Post Scriptum on Additional use of the data
I do not have the intention to try and publish any of the above in the peer reviewed scientific literature. However, feel free to contact me if you like to bring the analysis to a level that is fit for that. If you can make a convincing case that you indeed can, I’m happy to share the data and my scripts with you. Contact me through email at jan@forecastverification.com.






0 comments